We often hear that our production system is “IO-bound”. But what does that actually mean? It is a situation where the computational speed is hindered by the time spent waiting for input/output (IO) operations to finish. In other words, a task that processes the data from the disk could be IO-bound if the progress is limited by the speed of the I/O.
Table Space Information
Let’s take the example of a massive table with approximately 13 TB size having ~50 billion rows. In this instance, we are not using the Partitioning column in our predicates.
Table Definition
Query Explain
During a query execution analysis, it was identified that the optimizer executed an aggregation step at a specific stage by performing a comprehensive scan of a large table. Simultaneously, we noticed another issue during this step: the optimizer lacked confidence in the execution because the DGTL_TXN_DT column, used in the predicate, is not a partitioned key column.
DBQL Information
During a query execution analysis, it was identified that the optimizer executed an aggregation step at a specific stage by performing a comprehensive scan of a large table. Simultaneously, we noticed another issue during this step: the optimizer lacked confidence in the execution because the DGTL_TXN_DT column, used in the predicate, is not a partitioned key column.
Query Step Information
We observed that the SUM step was taking ~18.7 million IOs estimated rows. It indicates that the optimizer did not have up-to-date table statistics. Below are the query step details:
Recommendations
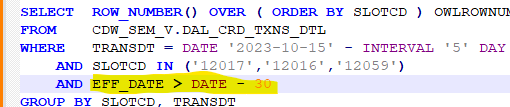
To address this situation, employing partition elimination or pruning is advantageous. By incorporating the partitioned column EFF_DT in the WHERE query condition, we can save a significant amount of IOs.
If a design modification is feasible, consider establishing a Partitioned Primary Index (PPI) on the TRANSDT column so that our query doesn’t scan all partitions but uses several IOs. It is essential to gather updated statistics so that the optimizer may generate an accurate execution plan.
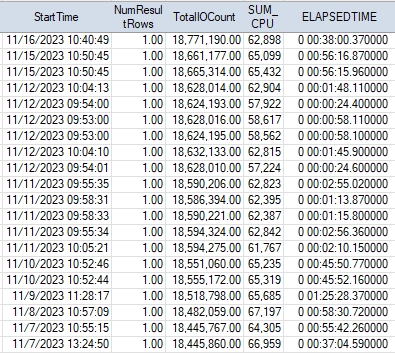
Savings
We were able to save a lot of computing resources (CPU and IO) and drastically reduce the report execution time.
Conclusion
In this blog, we’ve tackled the challenge of excessive I/O usage in a daily report. We identified inefficiencies like full table scans and the need for proper indexing and then implemented solutions like partition elimination and PPI creation.
By applying these techniques, we slashed IOs significantly and dramatically reduced report execution time.
Remember, optimizing data access can profoundly impact your system’s performance and resource utilization. Always look out for opportunities to refine your queries, leverage indexing strategies, and partition columns where applicable, and you will be well on your way to streamlined data operations.
Mubasher Hassan
Mubasher, at TenX works as Principal Performance Analyst