


Introduction
In the rapidly evolving landscape of big data processing, the transition from traditional MapReduce framework to the innovative Apache Spark platform marks a major shift. As organizations tackle the challenges of ever-expanding datasets, Spark has emerged as a widely embraced solution. With its unparalleled speed and efficient architecture, Spark has gained global popularity with its ability to handle skewed data, optimize cluster resources, and seamlessly distribute computation tasks across clusters.
Spark serves as an open-source analytics engine for big data and machine learning. Its diverse array of configuration options empowers companies to tailor their usage according to specific requirements, enabling them to extract insights and respond to queries within remarkably efficient timeframes.
In this blog we will be diving deep into Spark and how to use it efficiently.
Spark Architecture
Spark adheres to the concept of driver and worker nodes with a cluster manager existing between the two layers.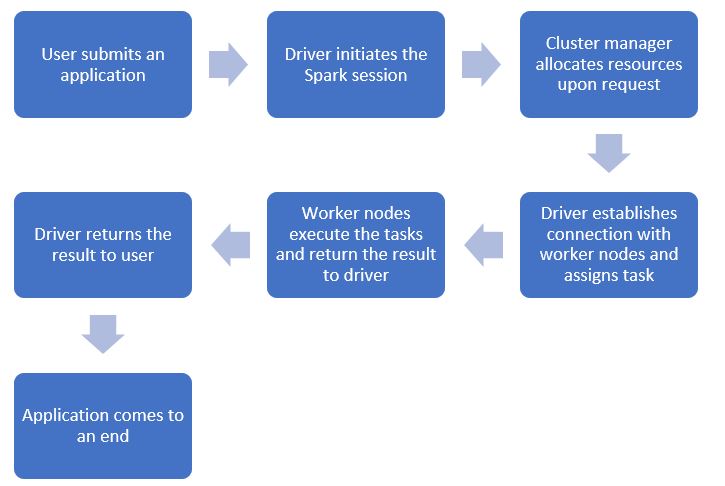
Spark architecture explained
- User command: When a user submits a command or a notebook as an application, the driver starts a Spark session.
- Conversion to a job: The system converts the application code into a job.
- Breakup into stages: Depending on the number of shuffles required, the job is broken up into stages, with each shuffling action producing a new stage.
- Division into tasks: Stages are broken down into individual tasks, each following the same logic within a stage. Each task can handle one partition at a time. RDDs/data frames are stored in the cluster’s memory as partitions.
- Allocation of Resources: The driver then communicates with the cluster manager to allocate resources.
- Assignment of Tasks: Once the resources are allocated, the driver establishes a connection with the worker nodes and assigns the task.
- Execution of Tasks: Depending on Spark settings, the worker nodes can potentially host multiple executors, with each executor being assigned multiple cores. Each single-threaded core can handle a single task or partition at a time.
- Returning the Results: Once the task is completed by the worker nodes, they deliver the outcome to the driver. The driver, in turn, sends the result to the user, bringing the application to a close.
Meanwhile, in the background, the cluster manager monitors the health of the worker nodes. When there is a decrease in the workload of the nodes, the cluster manager can remove or shut them down.
Memory Architecture
Within the worker nodes, each executor has access to the off-heap memory as well as its own on-heap memory. The on-heap memory is governed by JVM, whereas the off-heap memory is overseen by the operating system. The following areas make up the on-heap memory:
- Reserved memory: Spark sets aside memory for internal uses like fault recovery.
- User memory: Utilized to store objects produced by user code.
- Execution memory: Data structures use this to perform shuffle operations.
- Storage memory: Reserved for cached data.
The on-heap memory is used for small datasets, while larger datasets are kept in off-heap memory. Accessing off-heap memory is slower than on-heap, but it’s still faster than accessing the data from the disk.
Since the off-heap memory is managed by the operating system, it helps in avoiding the burden of data collection. However, as the data is stored in byte array format (serialized), there is an additional step of serialization/deserialization overhead.
To enable off-heap memory, a user needs to set spark.memory.offheap.use to True. The amount of off-heap memory that Spark is permitted to consume is specified by the spark.memory.offheap.size property.
What is a Cluster?
A cluster is a collection of computing resources and settings that work together to execute the tasks generated in the notebooks. The cluster has three modes:
- Standard: For a single user, this method is appropriate. We can use this mode if cooperation is not required.
- High concurrency: Collaboration is possible in this mode. It offers fine-grained sharing to maximize resource usage and improve query performance.
- Single node: In this mode, no worker nodes are provided, and the job is executed on the driver.
Types of Clusters
All-purpose cluster
All-purpose clusters, often referred to as interactive clusters, are used to run interactive notebooks for executing and analyzing data. We have the option to manually stop or start these clusters. Moreover, all-purpose clusters can also be shared by multiple users to conduct collaborative analysis.
Job cluster
Robust automated jobs run on job clusters. They are automatically created at the beginning of an execution and are terminated at the end of it.
A cluster can be connected to a databricks pool that – by keeping a set of idle, ready-to-use instances – speeds up cluster startup and auto-scaling times. Cluster nodes are built utilizing the pool’s idle instances when a cluster is attached to it.
Autoscaling
Databricks uses a performance optimization technique called autoscaling. This enables it to dynamically select the number of worker nodes to run a job based on the configured range of workers. Two kinds of autoscaling exist:
Optimized autoscaling
Through this autoscaling approach, a cluster is scaled from minimum to maximum in two steps. For job clusters, scaling down occurs if the cluster has been underutilized for the previous 40 seconds, while for all-purpose clusters, the threshold is 150 seconds. By examining the shuffle file state, a cluster can be scaled down even when it is not idle.
Standard Autoscaling
Beginning with the addition of 8 nodes, it scales up exponentially in a series of steps to reach the maximum value. Meanwhile, if a cluster has been fully inactive and underutilized for the previous 10 minutes, it is scaled down exponentially, starting from a single node.
Spark’s relationship with cluster behavior is central to its exceptional performance and efficiency in processing large-scale data. At its core, Spark operates by distributing data and computation tasks across multiple nodes within a cluster. This distributed nature enables Spark to take full advantage of the combined processing power and resources of the cluster, resulting in significantly faster data processing and analysis. Spark is an ideal platform for handling complex and resource-intensive data processing task

