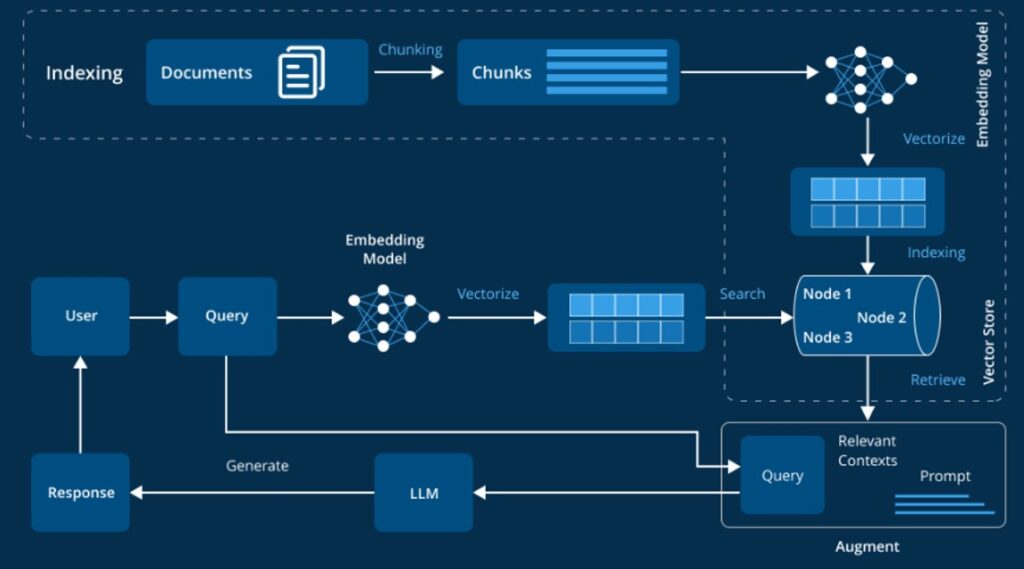
Advantages of RAG (Retrieval-Augmented Generation)
- Dynamic access to external knowledge bases
- Reduces hallucinations by grounding output in real data
- Easy to update knowledge (no need to retrain the model)
- Works well with unstructured data (PDFs, articles)
- Dynamically updated (no retraining required)
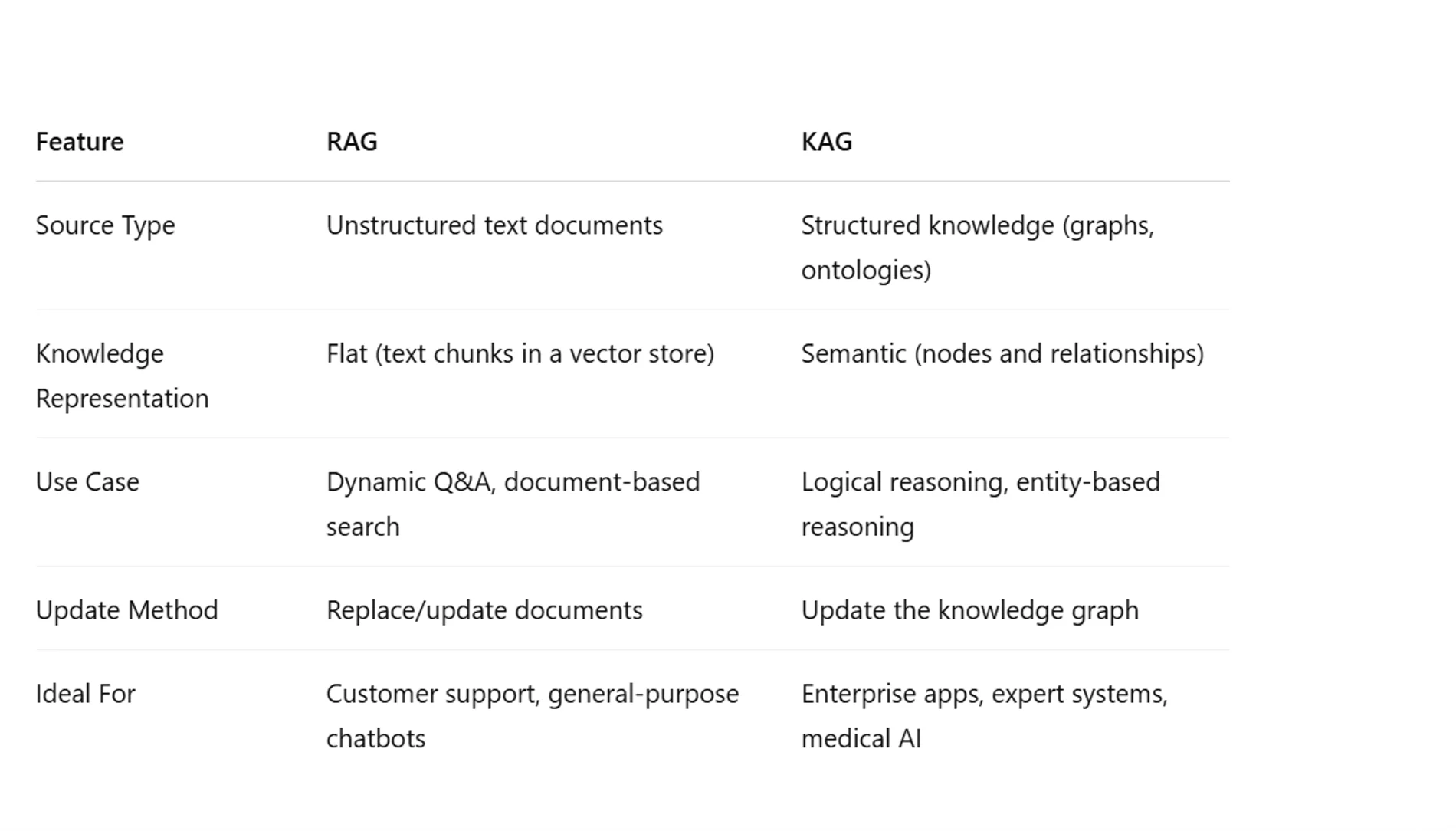
What is KAG (Knowledge Augmented Generation)
Knowledge Augmented Generation (KAG) integrates structured knowledge (like knowledge graphs) into the generation process. KAG is a broader paradigm that refers to integrating structured or semi-structured knowledge into the generative process. This could include: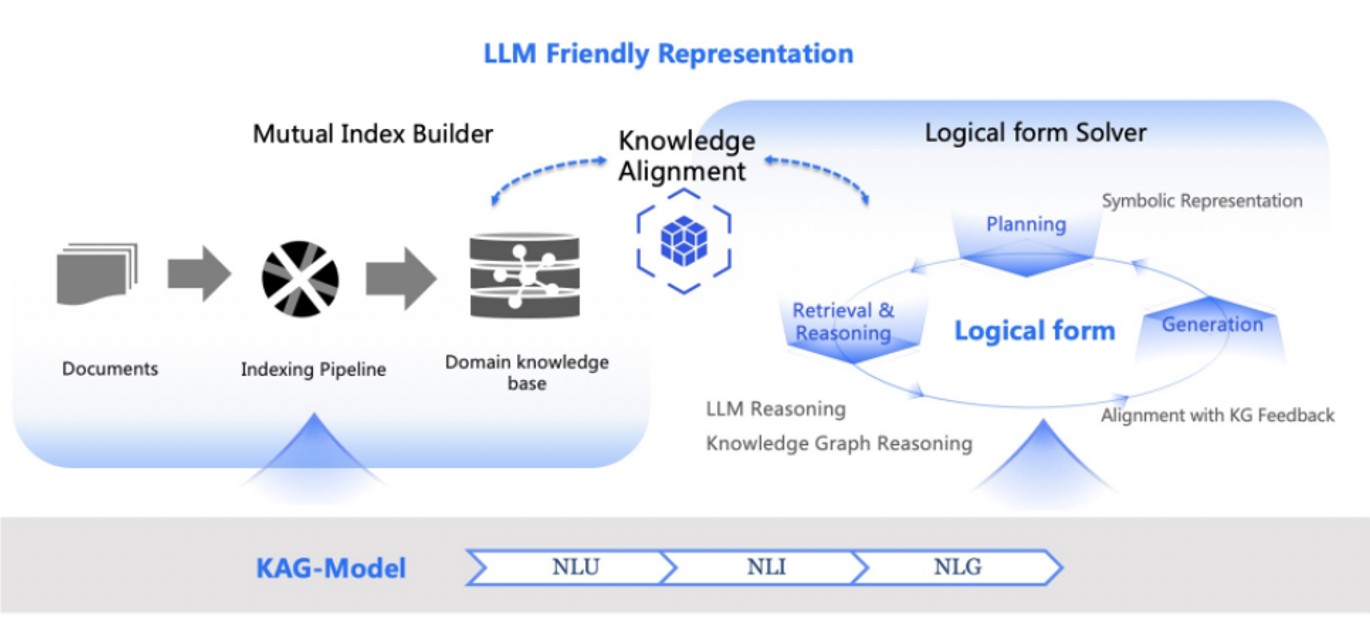
- Knowledge graphs (e.g., Wikidata, Neo4j)
- Ontologies
- Relational databases
- Domain-specific taxonomies
KAG acts more like a student using flashcards or a concept map — it relies on structured frameworks of information to generate meaningful and consistent outputs.
Advantages of KAG (Knowledge-Augmented Generation)
- Enforces logical consistency
- Useful when reasoning over entities and relationships
- Ideal for highly factual or domain-specific queries
- Better at reasoning and inference
- Ideal for domain-specific tasks (e.g., healthcare, law, enterprise systems)
So, What’s the Difference?
Use Case Examples
RAG (Retrieval-Augmented Generation) Use Case in Action:
A legal chatbot that fetches case law from a database and generates summaries or responses grounded in those documents.
KAG (Knowledge Augmented Generation) Use Case in Action:
A medical assistant who uses a clinical ontology to suggest drug interactions or diagnoses based on structured relationships.
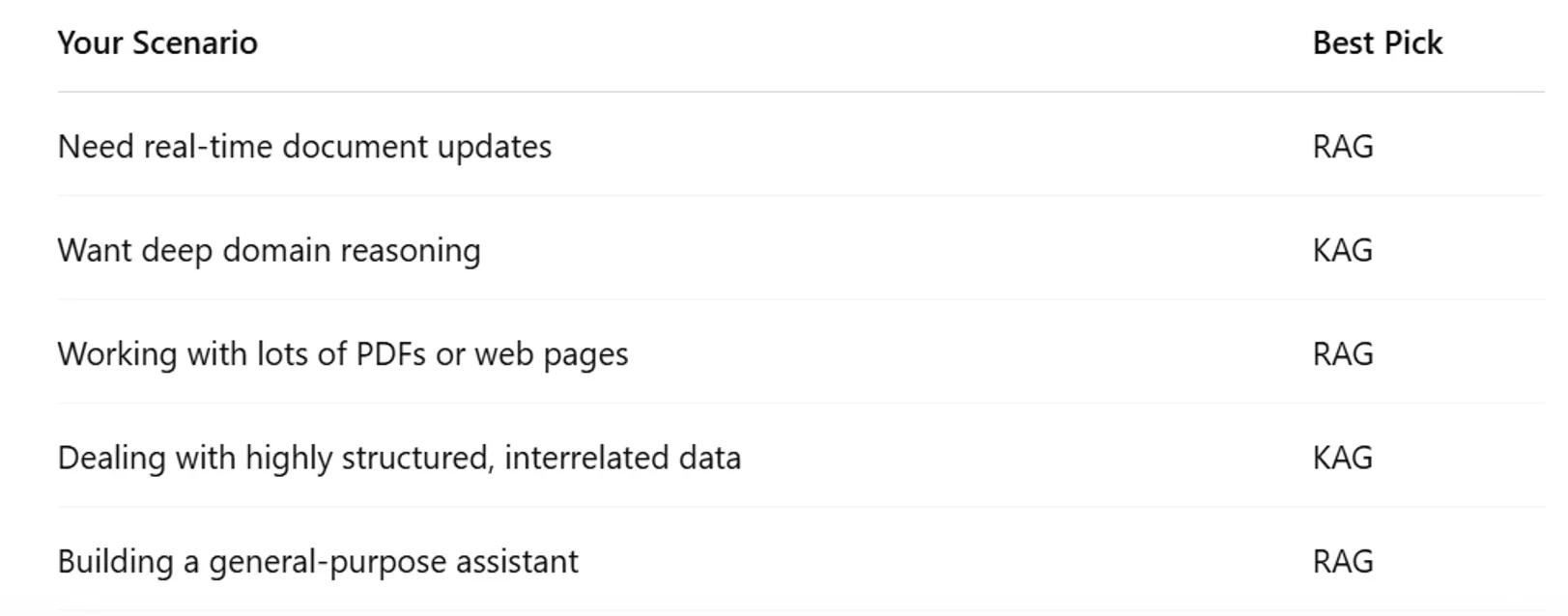
When to Use Which?
Can You Combine Them?
Absolutely. Some of the most powerful AI systems combine both:
- Use RAG (Retrieval-Augmented Generation) to bring in context from documents
- Use KAG to validate or enrich output using structured knowledge
This hybrid approach ensures both depth and accuracy — think of it as bringing together the best of both worlds.
Application: Medical Q&A Assistant
Demonstration by implementing a medical Q&A bot with both RAG and KAG (Knowledge-Augmented Generation) for answering a query. Let’s build a simple assistant that answers the question:
Question: “What are the side effects of ibuprofen?”
We’ll implement this using:
- RAG (documents from a medical dataset)
- KAG (a small medical knowledge graph)
We’ll compare RAG and KAG by answering this question using:
- A vector store-backed RAG (upgraded to use SentenceTransformers)
- A compact but complete RDF-based KAG system
We’ll also show the expected output from both approaches.
Step 1: Setup Environment
Install required libraries and set API keys. Make sure to set your OpenAI API key as an environment variable.
pip install langchain openai faiss-cpu transformers sentence-transformers rdflib
export OPENAI_API_KEY=”your-api-key”
Step 2: RAG (Retrieval-Augmented Generation) Implementation
Use a vector database and retrieve documents to answer queries. We’ll use a few medical text snippets and store them in a vector database (FAISS), then retrieve relevant info based on the query.
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
# 1. Sample medical content
docs = [
“Ibuprofen may cause nausea, dizziness, headache, and gastrointestinal bleeding.”,
“Ibuprofen is commonly used to reduce fever and relieve pain or inflammation.”,
“Side effects of ibuprofen can include stomach pain, constipation, or ulcers in rare cases.”
]
# 2. Split and wrap documents
splitter = CharacterTextSplitter(chunk_size=150, chunk_overlap=20)
documents = splitter.create_documents(docs)
# 3. Initialize embedding model and vector store
embedding_model = HuggingFaceEmbeddings(model_name=”sentence-transformers/all-MiniLM-L6-v2″)
vectorstore = FAISS.from_documents(documents, embedding_model)
# 4. Create retrieval-based QA chain
retriever = vectorstore.as_retriever(search_type=”similarity”, search_kwargs={“k”: 2})
llm = OpenAI(temperature=0)
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
# 5. Query
query = “What are the side effects of ibuprofen?”
response = qa.run(query)
print(“\n[🔍 RAG Output]”)
print(“Question:”, query)
print(“Answer:”, response)
# Optional: show retrieved docs
print(“\n[📚 Top Retrieved Passages]”)
docs = retriever.get_relevant_documents(query)
for i, d in enumerate(docs, 1):
print(f”{i}. {d.page_content}”)
[RAG Output]
Question: What are the side effects of ibuprofen?
Answer: Ibuprofen may cause nausea, dizziness, headache, and gastrointestinal bleeding.
[Top Retrieved Passages]
1. Side effects of ibuprofen can include stomach pain, constipation, or ulcers in rare cases.
2. Ibuprofen may cause nausea, dizziness, headache, and gastrointestinal bleeding.
- Using a Sentence-BERT model (all-MiniLM-L6-v2) improves semantic similarity retrieval
- We retrieve the top 2 chunks for better grounding
- The LLM (OpenAI) generates responses using real text chunks
Step 3: KAG (Knowledge-Augmented Generation) Implementation
Build a basic RDF graph and use SPARQL to query the side effects of ibuprofen.
from rdflib import Graph, Namespace, URIRef, Literal
# 1. Initialize graph and namespace
g = Graph()
EX = Namespace(“http://example.org/”)
# 2. Create entity
ibuprofen = URIRef(EX[“Ibuprofen”])
# 3. Add side effects to the graph
side_effects = [
“Nausea”, “Dizziness”, “Headache”,
“Stomach Pain”, “Constipation”, “Ulcers”
]
for effect in side_effects:
g.add((ibuprofen, EX.hasSideEffect, Literal(effect)))
# 4. Run SPARQL query
query = “””
SELECT ?effect WHERE {
<http://example.org/Ibuprofen> <http://example.org/hasSideEffect> ?effect .
}
“””
results = g.query(query)
# 5. Print results
print(“\n[🧠 KAG Output]”)
print(“Question: What are the side effects of ibuprofen?”)
print(“Answer:”)
for row in results:
print(“-“, row.effect)
[KAG Output]
Question: What are the side effects of ibuprofen?
Answer:
– Nausea
– Dizziness
– Headache
– Stomach Pain
– Constipation
– Ulcers
- RDF is great for deterministic, fact-based output
- No LLM hallucinations — perfect for critical fields like healthcare
Which One Works Best?
Final Verdict
KAG (Knowledge-Augmented Generation) is more suitable for structured, factual queries. RAG is flexible for open-ended queries. For the medical Q&A case:
- KAG gives precise and reliable answers with almost no hallucination
- RAG (Retrieval-Augmented Generation) is more flexible and can work even without structured knowledge
💡 Best choice for this task: KAG, since the question is factual and entity-based, and the knowledge is well-defined.
Winner for medical side-effect queries: KAG (Knowledge-Augmented Generation)
But for open-ended, context-rich queries, RAG (Retrieval-Augmented Generation) has more flexibility.
Bonus: Combine RAG + KAG
Using RAG for dynamic context and KAG for factual grounding yields the best results. You can combine both systems:
- Use RAG (Retrieval-Augmented Generation) to fetch context.
- Use KAG to verify or enrich the results. This hybrid model is powerful for enterprise applications.
📦 How to Run
Save the files:
Run both files side by side:
python rag_app.py
python kag_app.py
You’ll clearly see the contrast in output quality, depth, and reasoning style. You’ll get outputs like:
[RAG] Answer: Ibuprofen may cause nausea, dizziness, headache, and gastrointestinal bleeding.
[KAG] Side effects of Ibuprofen:
– Nausea
– Dizziness
– Headache
– Stomach Pain
– Constipation
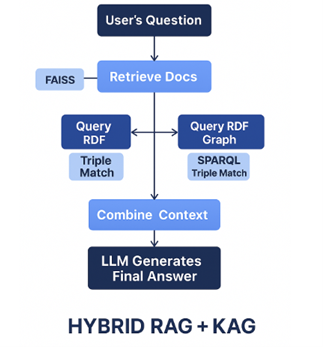
Architecture of Hybrid RAG + KAG
Let’s create a hybrid RAG + KAG system where:
- RAG (Retrieval-Augmented Generation) handles open-ended, contextual search (e.g., “Is ibuprofen safe during pregnancy?”)
- KAG injects structured, factual data (e.g., known side effects or contraindications).
- The final answer is produced by an LLM grounding that uses both retrieved documents and structured knowledge facts.
Hybrid RAG + KAG Pipeline
Combine both systems by merging retrieved unstructured and structured facts into the LLM output. 📦 The RAG + KAG pipeline for Medical Q&A Assistant
pip install langchain openai faiss-cpu sentence-transformers rdflib
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from rdflib import Graph, Namespace, URIRef, Literal
# —————– STEP 1: Vector Database (RAG) —————–
rag_docs = [
“Ibuprofen may cause nausea, dizziness, headache, and gastrointestinal bleeding.”,
“Ibuprofen is commonly used to reduce fever and relieve pain or inflammation.”,
“Side effects of ibuprofen include stomach pain, constipation, or ulcers.”,
“Ibuprofen should be used with caution during pregnancy, especially in the third trimester.”
]
splitter = CharacterTextSplitter(chunk_size=150, chunk_overlap=20)
documents = splitter.create_documents(rag_docs)
embedding_model = HuggingFaceEmbeddings(model_name=”sentence-transformers/all-MiniLM-L6-v2″)
vectorstore = FAISS.from_documents(documents, embedding_model)
retriever = vectorstore.as_retriever(search_kwargs={“k”: 2})
# —————– STEP 2: Knowledge Graph (KAG) —————–
g = Graph()
EX = Namespace(“http://example.org/”)
ibuprofen = URIRef(EX[“Ibuprofen”])
side_effects = [“Nausea”, “Dizziness”, “Headache”, “Stomach Pain”, “Constipation”, “Ulcers”]
pregnancy_warning = “Use with caution during pregnancy, especially in third trimester”
for effect in side_effects:
g.add((ibuprofen, EX.hasSideEffect, Literal(effect)))
g.add((ibuprofen, EX.hasWarning, Literal(pregnancy_warning)))
# Query knowledge graph
def query_kag(entity: str) -> str:
query = f”””
SELECT ?p ?o WHERE {{
<http://example.org/{entity}> ?p ?o .
}}
“””
results = g.query(query)
output = “”
for row in results:
prop = row.p.split(‘#’)[-1] if “#” in row.p else row.p.split(‘/’)[-1]
output += f”{prop.replace(‘has’, ”).replace(‘Effect’, ‘ effect’).replace(‘Warning’, ‘ warning’)}: {row.o}\n”
return output.strip()
# —————– STEP 3: RAG + KAG Merge —————–
query = “What are the side effects of ibuprofen and is it safe during pregnancy?”
# RAG context
rag_contexts = retriever.get_relevant_documents(query)
rag_text = “\n”.join([doc.page_content for doc in rag_contexts])
# KAG context
kag_text = query_kag(“Ibuprofen”)
# Final context for LLM
final_context = f”### Retrieved Info (RAG):\n{rag_text}\n\n### Knowledge Graph Info (KAG):\n{kag_text}”
# —————– STEP 4: Prompt & LLM Answer —————–
template = PromptTemplate(
input_variables=[“context”, “question”],
template=”””
You are a medical assistant.
Given the context below, answer the question factually and clearly.
{context}
Question: {question}
Answer:”””
)
llm = OpenAI(temperature=0)
chain = LLMChain(llm=llm, prompt=template)
response = chain.run({
“context”: final_context,
“question”: query
})
# —————– STEP 5: Display Result —————–
print(“\n🧠 [HYBRID RAG + KAG OUTPUT]”)
print(“Question:”, query)
Sample Output:
[HYBRID RAG + KAG OUTPUT]
Question: What are the side effects of ibuprofen, and is it safe during pregnancy?
Combined Context:
### Retrieved Info (RAG):
Ibuprofen may cause nausea, dizziness, headache, and gastrointestinal bleeding.
Ibuprofen should be used with caution during pregnancy, especially in the third trimester.
### Knowledge Graph Info (KAG):
Side effect: Nausea
Side effect: Dizziness
Side effect: Headache
Side effect: Stomach Pain
Side effect: Constipation
Side effect: Ulcers
Warning: Use with caution during pregnancy, especially in third trimester
📝 Final Answer:
Ibuprofen may cause side effects such as nausea, dizziness, headache, stomach pain, constipation, ulcers, and gastrointestinal bleeding. It should be used with caution during pregnancy, particularly in the third trimester.
Final Thoughts
As LLMs evolve, the line between unstructured and structured knowledge will become increasingly blurred. Mastering both RAG and KAG lets you build:
- Trustworthy assistants
- Domain-specific agents
- Explainable enterprise tools
In most real-world cases, the best solution lies in a hybrid approach.
RAG and KAG are not competitors — they’re complementary tools in the AI toolkit. Understanding when and how to use them can make the difference between a chatbot that guesses and one that truly understands.
Both RAG and KAG are shaping the next generation of AI systems. Your choice depends on your needs:
- Use RAG (Retrieval-Augmented Generation) for flexibility, natural language documents, and open-domain questions
- Use KAG (Knowledge-Augmented Generation) for reliability, structured reasoning, and factual accuracy
The future lies in their combination , where structured knowledge meets dynamic retrieval.
As large language models evolve, architectures like RAG (Retrieval-Augmented Generation) and KAG (Knowledge-Augmented Generation) will play an increasingly important role in grounding, reasoning, and trustworthy AI. So next time you’re building an AI system — ask yourself not just what your model knows, but how it knows it.