Feb, 2025
Retrieval Augmented Generation (RAG): Fixing AI’s Biggest Weaknesses

- Ali Ahmad
SHARE THIS
Introduction
Generative AI has revolutionized industries, but even the most advanced Large Language Models (LLMs) face significant challenges: outdated information, hallucinations, and high retraining costs. Retrieval Augmented Generation (RAG) addresses these limitations. RAG is a groundbreaking framework that enhances LLMs by integrating real-time, external data retrieval.
This article will provide an in-depth, engaging, and practical guide to the RAG system, including its architecture, benefits, and use cases, alongside unique insights, visuals, and implementation strategies.
Through this guide, I aim to surpass existing content by offering a comprehensive yet digestible explanation that ensures you’re equipped with everything needed to understand and deploy the RAG model.
A Conversation Between Doctor and Chatbot (Trained on Medical Field Data
Bot: Hey, doctor, how may I help you?
Dr.: I have a patient. She has a black mark below her eye. She was affected by COVID-19 in 2019 and recovered with some medicine, but I am not sure which one. This black mark has a purple shade on the edges and redness in the center. I think it might be a side effect of the medication. Do you know anything about this?
Bot: Yes, this black mark you describe looks like a place on Mars. Here are the details…
Dr.: What?
A humorous but concerning scenario highlights what happens when you rely on an LLM that lacks access to the latest documents and is trained on limited data.
LLMs are trained on vast datasets, but once their training is complete, they cannot automatically acquire new information. This raises the question:
- Do we need to retrain LLMs every time new information emerges constantly?
- Wouldn’t this consume excessive computational resources?
No. This is where Retrieval Augmented Generation (RAG) comes in to resolve the problem.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is an AI architecture that improves the accuracy and relevance of LLM outputs by retrieving information from external data sources during the text generation process. Unlike traditional LLMs, which rely solely on static training data, RAG allows models to dynamically access updated, domain-specific knowledge.
In simpler terms, RAG LLM acts like an AI-powered librarian, fetching the latest books (external data) to help the model craft its responses, ensuring accuracy and depth.
Why RAG is Essential for Modern AI
1. Real-Time Access to Updated Information
No matter how advanced, LLMs are limited to the data they were trained on. This often results in outdated or incomplete answers. RAG solves this by retrieving the latest data during query processing.
“RAG empowers AI models to stay informed, bridging the gap between historical knowledge and real-time updates.” – AI Research Analyst.
Example:
A medical chatbot powered by an LLM might provide outdated treatment information. By incorporating the RAG system, the model can pull the latest research papers or guidelines, ensuring patients receive accurate advice.
2. Reducing Hallucination and Improving Accuracy
A hallucination occurs when an LLM generates plausible yet incorrect or fabricated information. RAG LLM grounds the model’s output in factual, retrievable data, significantly reducing hallucination rates.
Example (from earlier):
Without RAG, the chatbot hallucinated that the patient’s black mark resembled a place on Mars. RAG LLM mitigates such responses by retrieving verified medical information.
Comparison Table: Fine-Tuned LLM vs. RAG-Augmented LLM
| Feature | Fine-Tuned LLM | RAG-Augmented LLM |
| Information Accuracy | Prone to hallucination | Grounded in real-time data |
| Retraining Frequency | Frequent | Minimal |
| Cost | High | Lower (retriever handles updates) |
| Response Relevance | Static | Context-aware, evolving |
How Does Retrieval Augmented Generation Work?
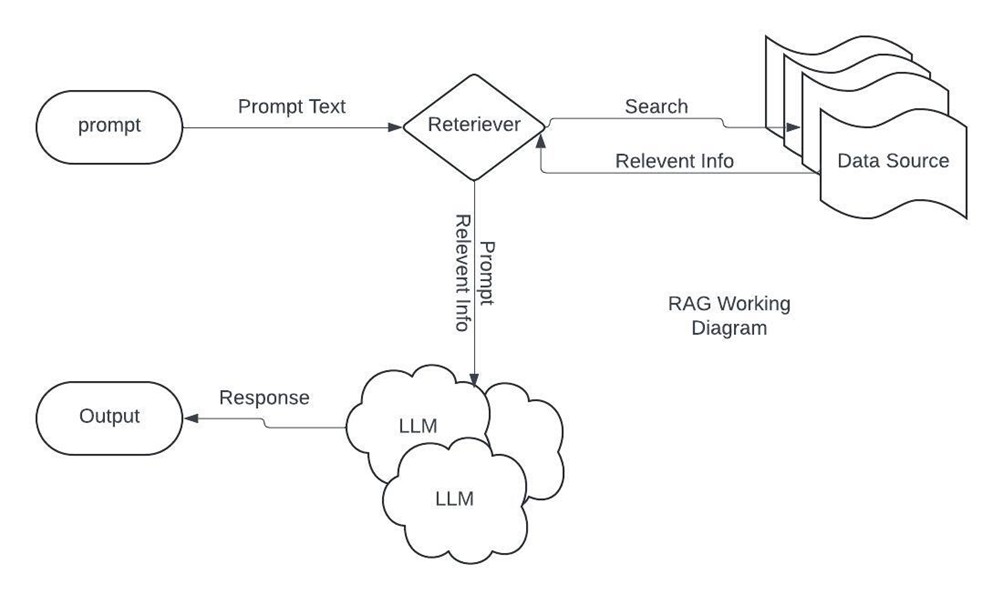
RAG’s workflow consists of four primary stages:
- Indexing and Data Preparation:
- Data (structured/unstructured) is converted into embeddings (vector representations) and stored in a vector database.
- Query and Retrieval:
- When a user submits a query, RAG uses a retriever module to fetch relevant documents from the vector database.
- Augmentation and Prompt Engineering:
- Retrieved data is incorporated into the LLM’s prompt, enriching the model’s context.
- Generation and Response:
- The LLM generates text based on both its internal parameters and the augmented information.
RAG in Action: Real-World Use Cases
1. RAG in Healthcare
Medical professionals can use RAG-powered chatbots to retrieve the latest treatment guidelines, drug information, and medical studies, ensuring up-to-date, trustworthy recommendations.
2. RAG in Legal: Document Analysis
Legal teams leverage RAG LLM to query case law databases, retrieve precedents and legal articles, and reduce the manual effort of document review.
3. E-commerce Personalization
Retailers use RAG to provide personalized recommendations by retrieving user behavior data, product catalogs, and customer reviews in real-time.
4. RAG in Customer Service
Customer service chatbots integrated with RAG can pull from internal documentation and previous support tickets to handle complex inquiries more accurately.
RAG vs. Transformers: Key Differences and Use Cases
Retrieval-Augmented Generation (RAG) and Transformers are both groundbreaking technologies in the AI landscape, but they address distinct challenges. Here’s a comparative breakdown:
Feature | RAG | Transformers |
Primary Function | Combines retrieval and generation for context-specific responses. | Focuses on generating text from a fixed input. |
Strengths | Handles real-time updates with external knowledge sources. | Excels in pre-trained tasks like language translation. |
Limitations | Dependent on the quality of the retrieval database. | Requires extensive training data for adaptability. |
Ideal Use Cases | Customer support, FAQ systems, knowledge management. | Text summarization, sentiment analysis. |
Key Takeaways:
- Use RAG when dynamic, context-specific responses are needed, especially in rapidly changing domains.
- Opt for Transformers for static text processing tasks where high-quality pre-trained models are available.
Challenges and Considerations
- Latency: Retrieval from large datasets can introduce response delays. Optimizing the vector database is crucial for performance.
- Data Quality: Poor or outdated data in the vector database can negatively impact results.
- Scalability: Implementing RAG at scale requires robust infrastructure, which may increase initial costs.
Final Thoughts
Retrieval Augmented Generation (RAG) represents the next evolution of LLMs, enabling accuracy, scalability, and adaptability that surpass traditional models. By integrating external data retrieval, the RAG model reduces hallucinations, enhances user trust, and lowers retraining costs.
Would you like to explore custom RAG solutions for your organization? Reach out, and let’s build the future of AI together.

Ali Ahmad
Ali Ahmad works as a Data Scientist at TenX
Global Presence
TenX drives innovation with AI consulting, blending data analytics, software engineering, and cloud services.
Ready to discuss your project?