

May, 2026
Systematic Data Quality: How to Build Trust Across Every Pipeline Layer

- Nabeel Fiaz
Establishing Data Trust: Systematic Validation and Quality AssuranceA practical guide to Data QA Engineering in modern data platforms.
Data QA Engineering is the foundation of trust in every modern enterprise data platform. By implementing systematic data quality assurance and observability you can prevent silent failures from compromising critical business decisions. This guide explores the engineering discipline required to maintain data integrity and transform information into a reliable strategic asset. When data fails without warning
Consider this scenario: your business dashboard shows a sudden spike in revenue. Leadership celebrates. Forecasts are revised. Strategic decisions are made — then, days later, a discrepancy surfaces. The same transactions were ingested twice due to a transformation error in the pipeline.
No application failed. No alert was triggered. Yet critical decisions were made on incorrect data.
automation projects.
This is the most dangerous kind of failure in modern systems — silent data failure.
In an era dominated by analytics, machine learning, and near real-time insights, Data QA Engineering plays a foundational role in ensuring that data is not only accessible, but reliable, consistent, and worthy of trust.
What is Data QA Engineering?
Data QA Engineering focuses on validating and assuring data quality across the entire data lifecycle — from ingestion at source systems through transformations, analytics, dashboards, and predictive models. Unlike traditional Quality Assurance, which primarily verifies application behaviour, Data QA evaluates the integrity of the data itself across four core dimensions:
- Accuracy — does data correctly represent real-world events?
- Consistency — is data aligned across systems and reports?
- Completeness and timeliness — are all expected records present and current?
- Transformation reliability — are business rules and calculations applied correctly?
Can the organisation confidently rely on this data to drive decisions?
Why data quality is a strategic imperative
Modern organisations depend on data to measure performance, guide product decisions, power AI and ML models, and satisfy regulatory requirements. At the same time, data architectures have evolved into highly distributed, interdependent systems — and each layer introduces additional complexity and risk.
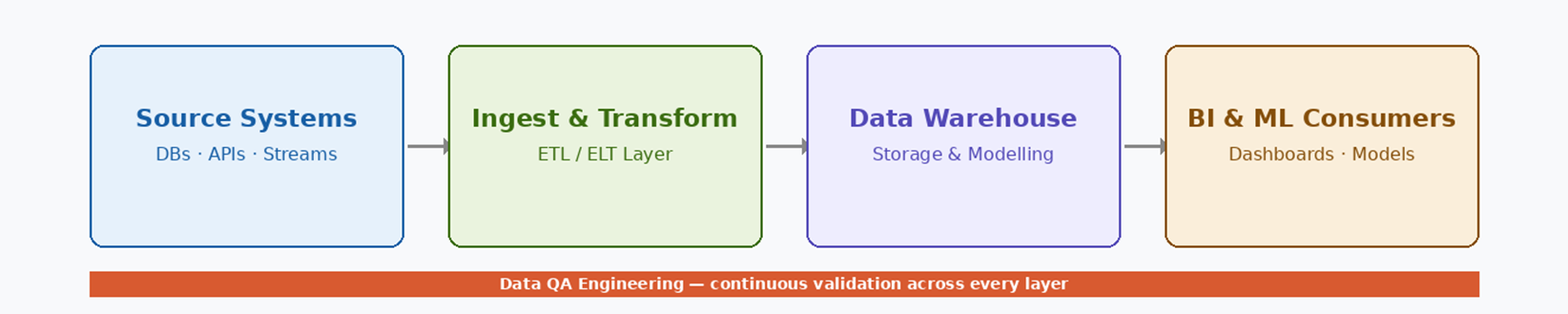
When data quality degrades at any point in this chain, the impact may not be immediately visible — but its consequences can be substantial. Bad data rarely causes system outages. It causes bad decisions.
How data flows: The Medallion Architecture
Modern data platforms structure their pipelines using the Medallion Architecture — a layered approach where data is progressively refined from raw ingestion through to curated, analytics-ready output. Each layer has a defined purpose, clear quality responsibilities, and its own QA validation checkpoint.
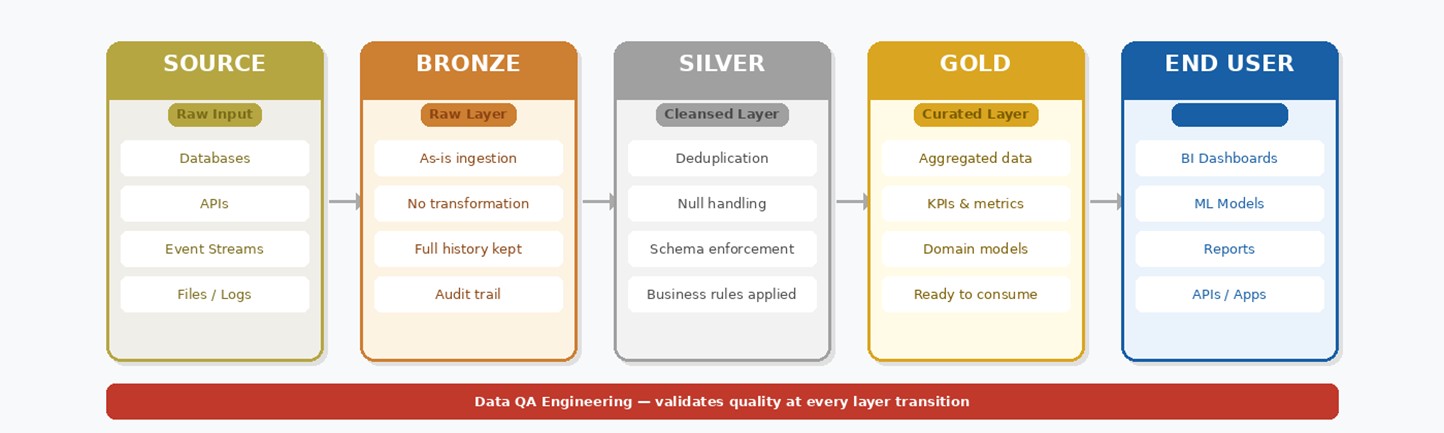
How data flows: The Medallion Architecture | ||||||||||
|
Raw data is a liability. Gold data is an asset. The layers in between are where quality is earned.
Why traditional testing falls short
These failures are particularly dangerous because they generate no exceptions, allowing incorrect data to propagate silently across systems:- Missing or null values that distort key metrics
- Duplicate records that inflate revenue or user counts
- Schema changes that silently break downstream logic
- Delayed or stale datasets leading to outdated reporting
- Data drift, where distributions shift gradually without detection
Advanced tooling and techniques
Data QA Engineering blends software engineering rigour with analytical judgement. The goal is not point-in-time testing but continuous data observability — an always-on view of quality across the entire pipeline:
- SQL-based rule validation and reconciliation checks
- Record counts and checksum comparisons between pipeline stages
- Threshold-based and statistical anomaly detection
- Trend, distribution, and variance analysis across time windows
- Automated quality checks embedded directly into data pipelines
- Monitoring and alerting for freshness, volume, and completeness
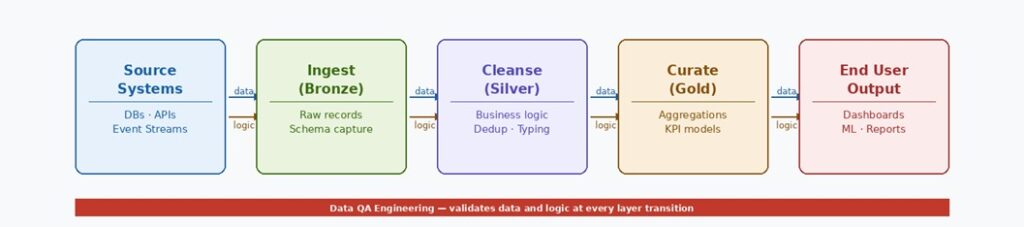
How data and logic flow across layers
Each layer in a data platform does two things simultaneously: it receives data from the layer above and applies logic before passing it forward. Understanding what moves between layers — and how — is essential for a Data QA Engineer to know where to intercept, validate, and assert quality.
Python & SQL — The dual engine of Data QA
SQL and Python are the two core tools of Data QA Engineering — not interchangeable, but complementary. SQL talks to data where it lives, validating it directly inside the warehouse. Python sits around the pipeline, orchestrating when checks run, handling results, and surfacing alerts. Together they form a complete quality assurance engine.
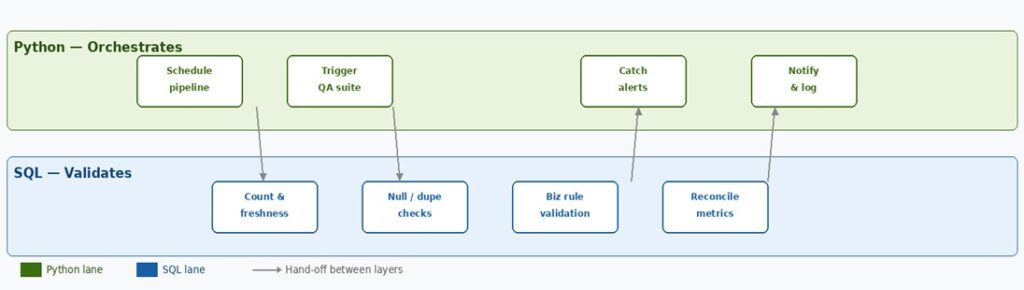
The practical insight: SQL tells you what is wrong with the data. Python tells you when, where, and who to notify. sThat combination is exactly what separates a QA tester from a Data QA Engineer.
Learning path for a Data QA Engineer
Phase | Focus | SQL Skills | Python Skills |
Phase 1 | SQL solid (months 1–2) | Nulls, dupes, counts, JOINs, CTEs, window functions | Not yet — SQL first |
Phase 2 | Python for automation (months 2–4) | Continue deepening validation patterns | pandas, pytest, script-based QA runners |
Phase 3 | Frameworks & pipelines (months 4–6) | dbt tests, reconciliation at scale | Great Expectations, Soda Core, Airflow basics |
Phase 4 | Observability (month 6+) | SQL monitors flag anomalies in real time | Python schedules checks and routes alerts |
An emerging and critical discipline
As organisations become more data-driven, the financial and reputational cost of poor data increases — and AI and ML systems amplify the impact of faulty inputs. Governance, auditability, and compliance demands are intensifying alongside this.
Despite this, Data QA Engineering remains an underdeveloped and often under-resourced discipline. Professionals who combine a QA background with deep understanding of data flows, transformations, and metrics are uniquely positioned to bridge this gap — making it both a high-impact role and a growing career path.
Data quality as a foundation for trust
Data QA Engineering sits at the intersection of engineering discipline, analytical thinking, and business accountability. Its success is often invisible — but its absence is always felt. As organisations increasingly rely on data for every strategic and operational decision, one reality becomes unavoidable:
Data without quality is not an asset — it is noise.
Building trust in data requires intentional, systematic, and continuous quality assurance. That responsibility belongs at the core of every modern data platform.
Key Takeaways |
▸ Data QA Engineering ensures accuracy, consistency, and reliability across the entire data pipeline. |
▸ The Medallion Architecture (Bronze → Silver → Gold) progressively refines raw data into trusted, analytics-ready output. |
▸ Each layer transition is a QA checkpoint — completeness, deduplication, schema, and metric validation. |
▸ Silent data failures — not system outages — are the greatest risk to data-driven organisations. |
▸ Continuous data observability, not point-in-time testing, is the modern standard. |
▸ SQL validates inside the pipeline; Python orchestrates around it — mastering both is the Data QA edge. |

Nabeel Fiaz
Nabeel Fiaz works as a Senior SQA Engineer at TenX

