SHARE THIS
There was a time when we barely heard that someone had become a Scientist. It suddenly created an image of “Intelligence Personified” in our minds. Undesirably, things have changed very fast in the last few years.
Now, in some parts of the world you see graduates with 2 years of experience being hired as data scientists. You just need to apply a couple of filters in the LinkedIn search bar to agree with me. It worries me – how can we become so irrational and allow this to happen? Even if the employer is overlooking this, how can the resource accept this? Even if the employer and resource both have been unreasonable, how can the customers allow this to happen by trusting such a professional services firm? These are just some of the questions that bother me!
This caused me to dissect the role of a Tabular Machine Learning Data Scientist to really understand what’s required to justify the title of “Data Scientist,” specifically in the context and limits of a tabular machine learning domain. Before you read further, please note that I am only writing this in the context of Tabular Machine Learning.
For those who are not familiar with Tabular Machine Learning, it’s a branch of machine learning focused on working with data organized in tables or spreadsheets. This data format, known as tabular data, typically consists of rows representing data points and columns representing features or attributes of those data points. Tabular ML can be used for classification, regression, recommendation systems, etc. Customer Churn Prediction and Fraudulent Financial Transaction Detection are just two widely discussed examples of Tabular Machine Learning Use Cases.
Unlike Computer Vision which requires images and videos data, and GenAI, which requires a huge amount of unstructured textual data, Tabular ML requires structured data with millions, if not billions, of data points that are used to develop features and train models.
After thoroughly considering the required ingredients for a Tabular ML Data Scientist Role, I have crafted the Venn Diagram below that depicts the skills needed. Similar diagrams have been created and shared in the industry for the last 10 years, so there is nothing proprietary about this Venn Diagram. However, this helped me visualize my thoughts on this subject to convey my message.
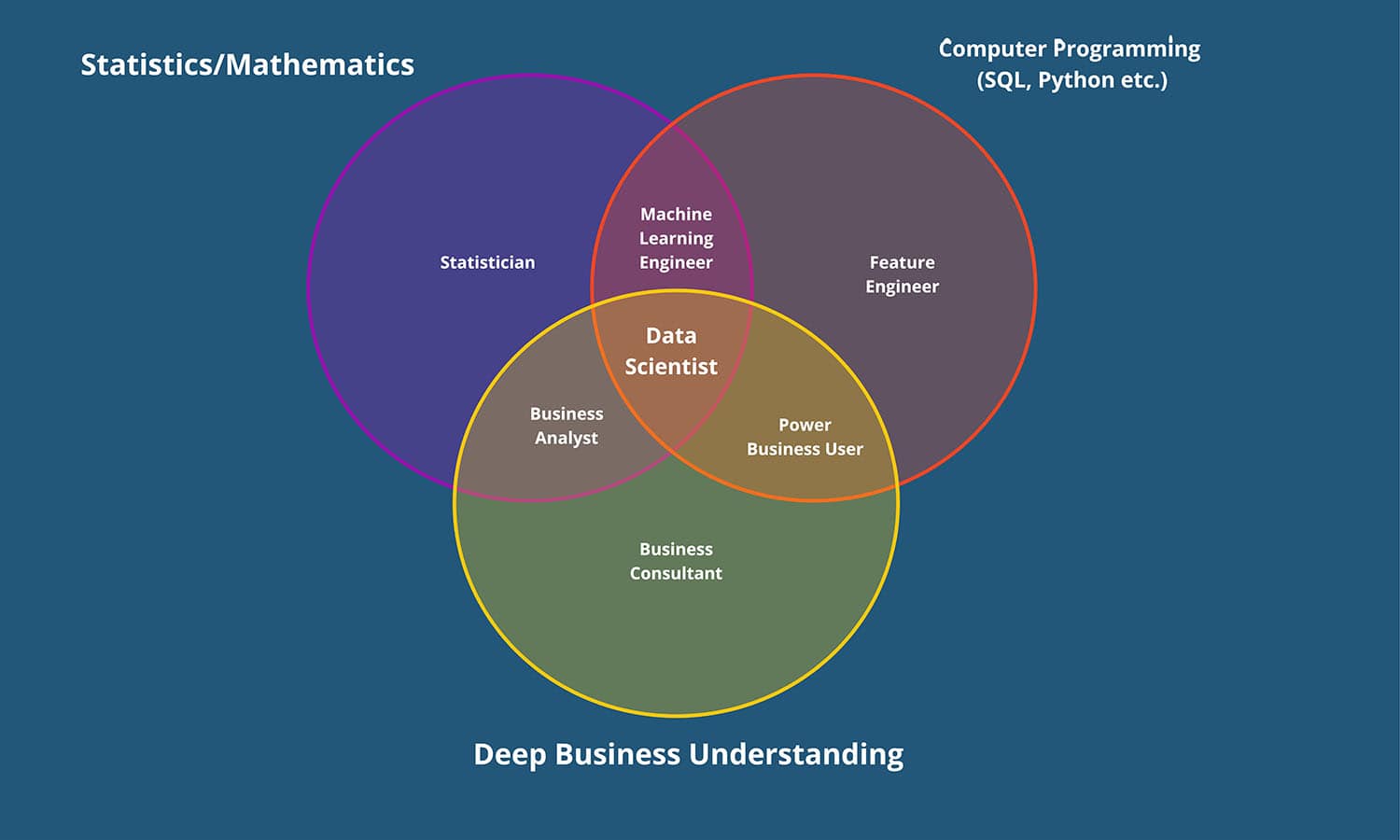
Figure 1 – Tabular ML Data Scientist Venn Diagram by Adnan Kazi, COO, TenX.
The three essential skills are:
Mathematics/Statistics
Mathematics and Statistics are the fundamental building blocks of data science. Statistical methods help you analyze data, identify patterns, and draw meaningful conclusions. Techniques like hypothesis testing, regression analysis, and clustering allow you to uncover hidden insights within datasets. Most machine learning algorithms used in data science rely heavily on math. From linear regression to deep learning, a strong foundation in math allows you to understand the underlying principles of these algorithms and how they work.
Therefore, Statistical/Mathematical knowledge is crucial for designing practical experiments to gather reliable data and test hypotheses.
Software Programming (SQL, Python, R, etc.)
SQL (Structured Query Language) is the primary language used to interact with tabular databases. It allows tabular data scientists to query the database, retrieve specific data subsets, and perform various operations on the data to identify patterns, important features and understand target variables for ML models.
On the other hand, hardcore programming languages like Python, R, etc., are imperative. Most machine learning algorithms are implemented within software libraries or frameworks. Programming skills are necessary to use these libraries, train models, evaluate their performance, and integrate them into applications. Data science projects often involve repetitive tasks. Programming allows you to automate data pipelines, streamlining the entire process from data acquisition to analysis and model deployment. This saves time and reduces the risk of errors.
Deep Business Understanding
Tabular data analysis often relies heavily on feature engineering, the process of creating new features from existing ones. Understanding the business context helps you identify meaningful features that capture the underlying business processes and relationships relevant to the problem you are trying to solve. Data science models can generate complex outputs. Business knowledge allows you to interpret these results in a meaningful way, connect them back to real-world business metrics, and identify actionable insights.
Now, let’s assume there is a person named Sara.
Suppose Sara is good at Mathematics/Statistics and Software Programming but doesn’t have a good understanding of the business/industry for which she is trying to develop an ML solution; she may be a Machine Learning Engineer but not a Data Scientist. She can run a bunch of algorithms on different features but won’t be able to drive real business value. Business knowledge helps identify features that capture the underlying business processes and relationships relevant to the problem you’re trying to solve. Features engineered without this context might be statistically exciting but not truly meaningful for the business problem, with almost no prediction power to make relevant decisions. I have seen a myriad of ML models deployed in the businesses but decommissioned later as they didn’t add any real business value and failed to gain the trust of the business users. I hope you now know one reason for this failure, having read this BLOG this far J.
Similarly, if she is good at Mathematics/Statistics and has a deep business understanding but is not a software programmer, she may be a good Business Analyst but not a Data Scientist.
The point is that she needs to be at the very intersection of Math/Stats, Software Programming with a deep Business Understanding to justify her title of “Tabular ML Data Scientist.”
Do you still need clarification on my argument?
Let me share another example to build my case further.
Let’s assume I’m making an ML model for Customer Churn Prediction for a Telecommunication Company. I will first need to define the Problem Statement specifically for this model. Without having a deep understanding how the telecommunication business works, what the customer lifecycle looks like, how customers normally behave, and what an outlier behavior is, amongst other things, I will fail in the very first step of the Machine Learning Model Development Cycle, i.e., Problem Definition/Understanding.
I will also want to understand if the model needs to classify any customer who shows signs of potential inactivity (reduced usage, missed payments) as a churner while they haven’t explicitly canceled yet. This allows for proactive intervention to retain these at-risk customers. After all, with a clear understanding of the problem, it’s easier to identify the features that genuinely influence the target variable. Otherwise, you may create irrelevant or redundant features, hindering the model’s ability to capture the underlying relationships. So, it is evident that my mathematical and statistical expertise and software programming skills, alone, will not help me without understanding the business.
Even if I find a cheat card on the problem definition, I won’t succeed in the next key step in the ML development cycle, Exploratory Data Analysis (widely known as EDA), to understand the key data points, trends, patterns and potential features in the data to train the prediction model. This is because I will see numbers but will not have the right business context to identify the right features.
Let’s slightly change the scenario. Let’s assume I have spent 10 years at a global telecommunication company, and my knowledge in this business domain is at least a mile deep, and I’m an excellent (self-proclaimed J) software programmer. What if I don’t understand probabilities, regression, decision trees, causality vs. correlation, expected value theory, statistical significance etc.? Obviously, I will not be able to shortlist the suitable ML algorithms to train my model. This effectively means, I will not be able to deliver a trustworthy ML Model.
Before I conclude this, I want to share something meaningful shared by Dr. Stephen Brobst, former Global CTO Teradata Corporation and Advisory Board Member, TenX. He said that another extremely important trait that great data scientists need is “Communication.” The ability to explain the results of data exploration without using mathematical terms. From his perspective, in many cases, it’s the ability to “communicate” to the business people that is a critical missing skill set among data scientists; sometimes, it can work to have an “intermediary” business analyst that serves as a communication channel between the data scientists and the business stakeholders.
Conclusion:
If you’re an aspiring Data Scientist interested in Tabular Machine Learning, sharpen your skills in the areas mentioned above to become a highly sought-after Tabular Data Scientist.
And remember, the journey is an ongoing process. It requires dedication and a commitment to continuous learning:
- Mentorship: Seek guidance from experienced professionals in the field.
- Hands-on Experience: Dive deep and gain practical experience by working on real-world projects.
- Education: Utilize a combination of instructor-led courses and online resources to solidify your knowledge.
- Professional Experience: Gain years of practical experience building and deploying commercial-grade machine learning solutions.
By mastering these steps, you can be in the spotlight at Fortune 100 companies worldwide!
If you want more details or want to share any feedback on this piece, hit me up at adnan@tenx.ai.
Happy Learning!
Acknowledgement:
I would like to thank Dr. Stephen Brobst, Advisory Board Member, TenX, for his thoughtful review and suggestions. His contributions have significantly enhanced the content of the blog. Stephen is one of the top-ranked CTOs in the US, a thought leader and arguably the world’s best tech speaker.

Adnan Kazi
Adnan is the COO of TenX
Global Presence
TenX drives innovation with AI consulting, blending data analytics, software engineering, and cloud services.
Ready to discuss your project?