November, 2025
The Complete Guide to Data Quality Assurance (QA) in Data Engineering

- Muhammad Musa Khan
Introduction
In today’s data-driven society, even a single incorrect record can confuse an entire analytics dashboard or lead to an inaccurate AI model prediction. This is why Quality Assurance (QA) in Data Engineering has become the most critical part of any data pipeline in modern times.
Gartner estimates that insufficient data costs an organization an average of $ 12.9 million annually. The effect doesn’t just end with financial gain – in fact, false data damages reputation, compliance, and informed decision-making.
Insufficient data can mislead analytics dashboards or produce incorrect AI model predictions. For deeper insight into how clean data powers AI systems, explore our guide on RAG vs KAG models.
This guide breaks down what Data Quality Assurance (QA) really means, why it’s essential, and how modern data teams can implement it step by step. Whether you’re new to data engineering or designing enterprise-grade pipelines, this framework will help you build clean, reliable, and trustworthy data systems.
What Is Data Quality Assurance in Data Engineering?
Data Quality Assurance (DQA) in data engineering helps ensure that data flowing through your pipelines is accurate, consistent, and reliable. This includes establishing validation controls, implementing cleaning procedures, and conducting periodic checks to identify errors before they reach analysts or business personnel.
To put it simply, QA is the process by which we ensure that the data we capture, process, and store accurately reflects the real world.
Without QA:
- Wrong insights cost businesses revenue.
- Redundant or absent data decelerates processes.
- AI and analytics models generate biased or inaccurate results.
By ensuring strong QA, data teams can ensure:
- Data integrity: accuracy and consistency across systems.
- Reliability of pipelines: fewer job failures.
- Minimization of errors: timely identification of bad records.
- Credible analytics: confidence in decision making.
Why Data Quality Assurance Matters More Than Ever
Data pipelines are becoming increasingly complicated with multiple data sources, cloud APIs, flat files, databases, and streams. All of these become possible points of failure.
Imagine:
- A minor change to the schema of a single source table causes an ETL job to fail.
- The missing value of a key field biases the machine learning prediction.
- Repeat records boost revenues.
Good QA is the safety valve that prevents these problems from reaching production.
Talend Data Quality claims that organizations with proactive QA can achieve 50 percent faster data delivery and a significant reduction in downstream errors.

Figure 1 is a visual overview of the five key QA stages from profiling to shadow testing.
Step 1: Data Profiling – Know Your Data
To validate or clean data, you must first understand it.
Problems detected by data profiling include missing values, duplicates, or anomalies, which can create downstream issues.
Common checks include:
- Rapid Null and duplicate detection
- Schema mismatches
- Categorical field cardinality
- Outlier identification
Example – Profiling Sales Data in Python

Tools like Great Expectations, Apache Griffin, and ydata-profiling help automate this process and generate visual reports on data quality.
Efficient QA workflows often rely on optimized code. If you’re working with Python for profiling or cleansing, our guide on Python data structures can help improve performance.
Step 2: Data Validation – Check the Rules
Once profiling is complete, the next step is data validation, ensuring that both the data form and logic are correct.
Validation may be separated into two layers:
- Technical Checks
- Schema validation (data types and columns)
- Null handling
- Primary key uniqueness
- Format validation (e.g., phone number or email)
- Business Logic Checks
- order_total = SUM(quantity * unit_price)
- discount_pct BETWEEN 0 AND 100
- end_date > start_date
Example – SQL Validation Query
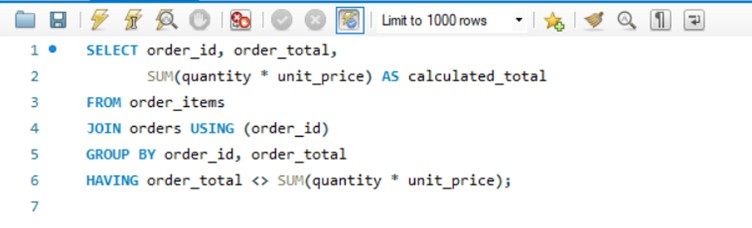
Technical and business validation work together to ensure that your data is not only syntactically correct but also accurate in context.
Modern data QA also benefits from AI-driven testing tools, which automate anomaly detection and improve overall coverage.
Step 3: Data Cleansing – Fix What’s Broken
Following the identification of problems, data cleansing aims at correcting them. The objective is to standardize and effectively use data.
Common actions:
- Remove duplicates
- Handle missing values (e.g., imputation or flagging)
- Standardize formats (dates, phone numbers, capitalization)
- Normalize text values
Example – Standardizing Phone Numbers

A cleaning process must never lose traceability, and teams must be able to track what was changed and the reason why it is essential in industries such as healthcare and finance.
Step 4: Continuous Monitoring – Don’t Set and Forget
QA of data is not a one-time task. Pipelines evolve, while schemas do not remain static, and new anomalies emerge.
Continuous monitoring ensures your data remains reliable day after day.
Metrics to track:
- Consistency in the count of records in stages
- False proportion of loose fields
- Schema evolution
- Data drift alerts
Example – Row Count Reconciliation

When counts are not equal, it signals a potential ETL issue before end users even realize it.
Step 5: Shadow Dataset Testing – The Hidden Power Tool
A promising yet underutilized current QA approach is shadow dataset testing, which involves developing miniature, representative samples of production data to validate them safely.
Benefits:
- Test new transformation logic safely
- Validate upgrades before production rollout
- Experiment with new business rules without disrupting live data
Example – Creating a Shadow Dataset

Think of a shadow dataset as a “sandbox” for your data pipeline, safe, isolated, and highly effective for QA experimentation.
Real-World Case Studies
E-Commerce
Problem: 15% revenue was misreported due to similar categories.
Solution: Automated category validation and cleansing.
Result: Accuracy improved to 99.2% due to stabilized revenue reporting.
Healthcare
Problem: 23% of patient records could not be matched across systems.
Solution: Shadow datasets applied with phonetic analysis and fuzzy matching.
Result: Record matching accuracy increased to 94%.
FinTech
Problem: The fraud detection model falsely flagged 12% of legitimate transactions.
Solution: Integrated Great Expectations with shadow testing.
Result: False positives decreased to 2.3%, and fraud detection accuracy remained at 97%.
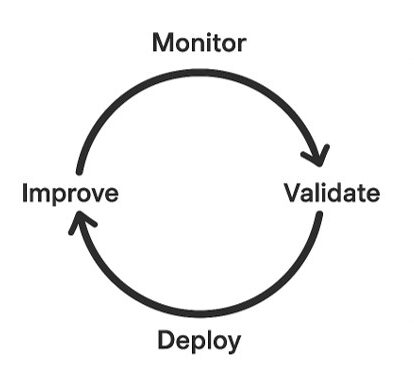
Quality assurance in data engineering is a continuous cycle of monitoring, validation, improvement, and deployment, as shown in Figure 2.
The Future of Data QA
Data Quality Assurance is evolving beyond manual validation. New technologies are now directed to automation and intelligence.
Trends shaping the future:
- AI-based anomaly detection:
Automatic detection of outliers with the help of ML.
- Data observability platform:
Monte Carlo Data and Soda Data are data observability platforms that monitor pipeline health in real time.
- Shift-left testing:
Incorporate QA sooner in the data development life cycle (e.g., CI/CD integration, dbt test hooks).
These innovations are transforming QA into a proactive, automated discipline rather than a reactive one.
Read More
Quick Start Checklist
- Begin with data profiling to understand the health of the data.
- Apply both technical and business validation rules
- Implement cleansing routines with audit trails.
- Set up continuous monitoring dashboards.
- Test on shadow datasets for safety.
- Implement automation where possible and integrate QA into CI/CD.
FAQ
- What is Data Quality Assurance in data engineering?
Data Quality Assurance ensures that data in pipelines is accurate, complete, and consistent by applying validation, cleansing, and monitoring techniques. - Why is data quality important?
Insufficient data leads to incorrect analytics, ML bias, failed pipelines, financial losses, and compliance risks. - What tools are used for data QA?
Popular tools include Great Expectations, dbt tests, Apache Griffin, Soda, Monte Carlo, and custom validation frameworks. - What is data profiling?
Data profiling analyzes datasets to identify structure, patterns, missing values, duplicates, and anomalies. - What is shadow dataset testing?It is a safe QA method using representative datasets to test new logic without impacting production data.
Conclusion:
Quality assurance is not a choice; it is the way that organizations develop trust in analytics, AI models, and data-driven decisions in the data engineering world.
With structured QA procedures, continuous monitoring, and modern tools, your data pipelines become resilient, reliable, and future-ready.
Data QA isn’t just about validation; it’s about confidence. Confidence that every dashboard, model, and report is powered by truth.

Muhammad Musa Khan
Musa Khan works as a SQA Analyst at TenX
Global Presence
TenX drives innovation with AI consulting, blending data analytics, software engineering, and cloud services.
Ready to discuss your project?